A language model captures the statistical characteristics of sequences of words in a natural language, typically allowing one to make probabilistic predictions of the next word given preceding ones. E.g. the standard “trigram” method:
In backoff, we use the trigram if the evidence is backoff sufficient, otherwise we use the bigram, otherwise the unigram. In other words, we only “backoff” to a lower-order N-gram if we have zero evidence for a higher-order N-gram.
For example if we are trying to compute but we have no examples of a particular trigram , we can instead estimate its probability by using the bigram probability . Similarly, if we don’t have counts to compute , we can look to the unigram .
So we can approximate
by the chain rule,
and limit the history (Markov order) like using 4-gram probability
Given a sequence of D words in a sentence, the task is to compute the probabilities of all the words that would end this sentence. The words are chosen from a given vocabulary (V).Object is learn a good model to compute the following conditional probability:
for any given example (). Each word is represented by a vector , which has the dimension of the dictionary size (). is a large but finite set. For example, consider the sentence:
In this case . Given {We, all, have} we need to compute the probability of getting {it} as the 4th word. Each word has an index in the vocabulary. For example:
which translates to the word vectors as follows: representing “We” will be a dimensional vector with the entry 91 being equal to 1, and all other entries equal to 0. Similarly, representing “all” will have its 1st entry equal to 1 and all others 0 etc.
So, indeces are based on one hot encoding.
A neural network would require an input layer with the size of the vocabulary, which could be very large. A traditional network would also require a huge number of neurons to calculate the probabilities, which would lead to a very large number parameters to be optimized. To avoid over-fitting, one needs a giant dataset for training which could make the problem intractable. This problem (a.k.a curse of dimensionality) can be circumvented by introducing word embeddings through the construction of a lower dimensional vector representation of each word in the vocabulary. This approach not only addresses the curse of dimensionality, but also results in an interesting consequence: Words having similar context turn out to have embedding vectors close to each other. For instance, the network would be able to generalize from
to
since “cat” – “dog”, “walking” – “running” , “bedroom” – “room” have similar contexts thus they are close to each other in the space of word embedding vectors.
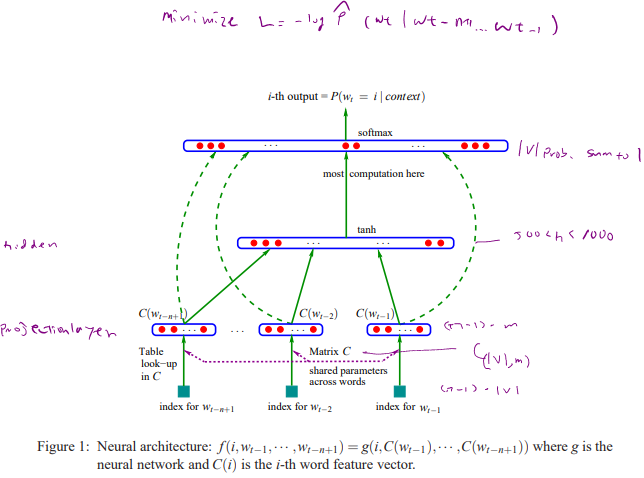
Bengio’s NNLM[1]
The input layer contains the indices of the words from the vocabulary and there are of them (since a training example has words, and the task is to predict the word to finish the sentence). Typically, , . The second layer is the projection layer (embedding layer), and transforms each input word (that has the dimension of the vocabulary ), into a lower dimensional vector representation (say ). There is one hidden layer with size , and the output layer has size which is then fed into a softmax function to compute the probability of each word in the vocabulary.
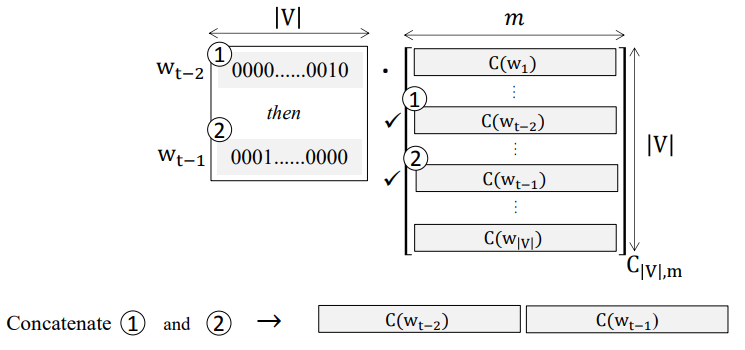
Passing from the input to the projection layer, one obtains an embedding vector for each of the D words that are stacked together to form the dimensional vector :
Here, the embedding weights are shared among all the words. In passing from the input layer with word indices to the projection layer resulting in , the operation shown above is a table lookup. Namely, for each given word index, one needs to find out which row in C its embedding is located. To make it clearer, let’s consider an example. Suppose we have a training batch with D=3 stacked in a matrix as follows:
Each column represents a training example: The 1st column represents the words given above. Given the word embeddings (determined through the training process), the table lookup involves unfolding the input_batch into a vector and subsetting the rows of C corresponding to each word in the vocabulary. Namely,
and
Now that the embedding vectors are obtained, we can feed forward through the network to compute probabilities.
Above can be also represented as the below figure.
contains the weight parameters that are tuned at each step. After training, it contains what we call the Word Vectors
*Softmax is used for the output layer. for unit in the output layer. Now is
where
Computationally costly:
Training is performed via stochastic gradient descent (learning rate ):
Token based text embedding trained on English Google News 200B corpus
Text embedding based on feed-forward Neural-Net Language Models[1] with pre-built out-of-vocabulary(OOV). Maps from text to 128-dimensional embedding vectors. Out-of-vocabulary (OOV) words are unknown words that appear in the testing speech but not in the recognition vocabulary. They are usually important content words such as names and locations which contain information crucial to the success of many speech recognition tasks
Example use
embed = hub.Module("https://tfhub.dev/google/nnlm-en-dim128/1") embeddings = embed(["cat is on the mat", "dog is in the fog"])
Based on Bengio’s NNLM with three hidden layers.
The module takes a batch of sentences in a 1-D tensor of strings as input.
The module preprocesses its input by splitting on spaces.
Small fraction of the least frequent tokens and embeddings (~2.5%) are replaced by hash buckets. Each hash bucket is initialized using the remaining embedding vectors that hash to the same bucket.
Word embeddings are combined into sentence embedding using the sqrtn combiner (see tf.nn.embedding_lookup_sparse).
[1] Yoshua Bengio, Réjean Ducharme, Pascal Vincent, Christian Jauvin. A Neural Probabilistic Language Model. Journal of Machine Learning Research, 3:1137-1155, 2003.