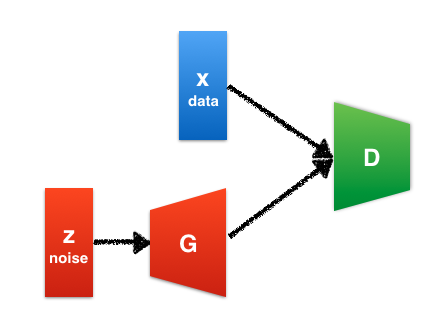
The generator G aim is to capture the data distribution, while the discriminator D estimates the probability that a sample came from the training data rather than G.
To learn a generative distribution over the data the generator builds a mapping from a prior noise distribution to a data space as to minimize . . The discriminator outputs a single scalar representing the probability that x came from real data rather than from .
In this context, we want to maximize with respect to the discriminator , that is, the part from equation 1 and minimize . So if can classify sample correctly, gets larger, and if can generates sample as close as sample , then becomes closer to 1 so gets closer to 0.
Algorithm from the original paper
