Attention Model
Motivation:
The motivation of attention model comes from the fact that the encoder/decoder of RNN needs to store the entire sentence in the encoder before decoder can make the prediction.
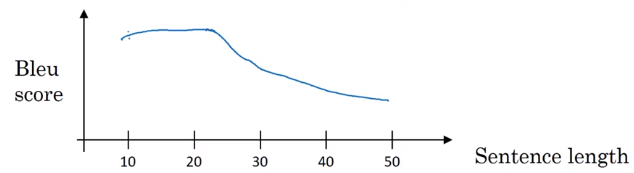
So, typically encoder/decoder performs well on the short sentence, but the BLUE score descreases as the sentence length get larger.
Attention model intuition
- Original paper on attention model
- Let’s start with this example:
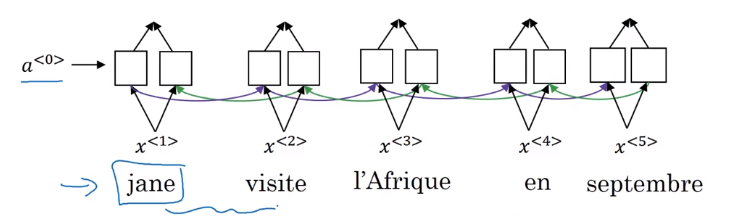
- In order to output the first word ‘Jane’, you need to look the first word in the input sentence.
- Attention model looks at the 'attention weight’
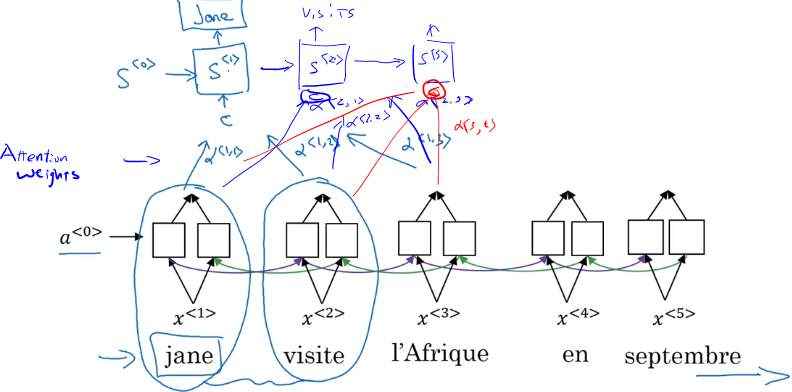
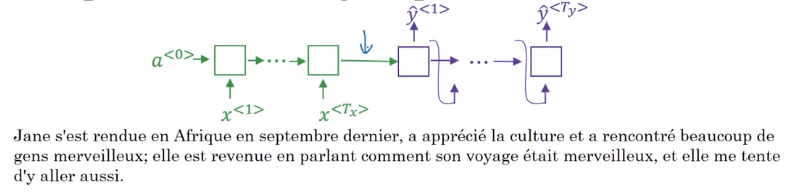
Attention model
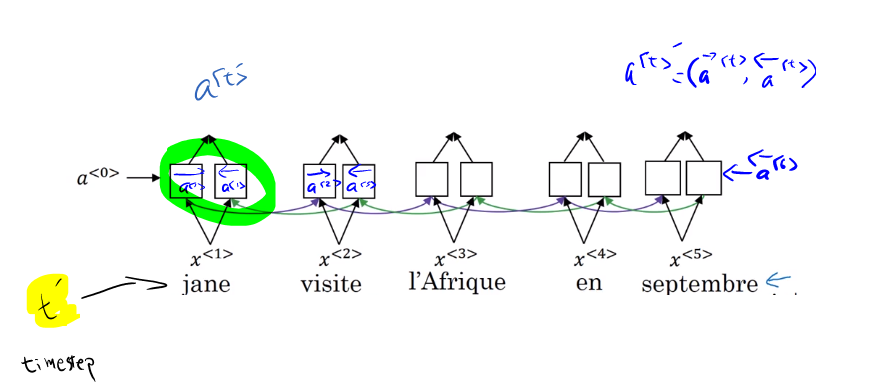
- Lets assume we have an input sentence and use bidirectional RNN, or bidirectional GRU, or bidirectional LSTM
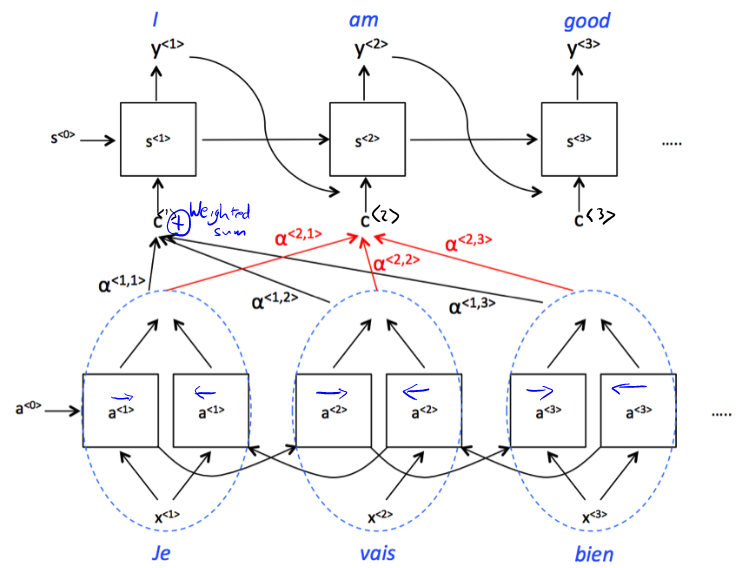
- The input to the second RNN are controlled by the attention weights, which denote the context that is considered by every single word to compute the translation.
- weights tell us how much the context would depend on the features we are getting, so the activations we are receving from the different time steps.
- context is the weighted sum of the attension weights.
- where
is the amount of ‘attention’ should pay to
Computing attention
- = amount of attention should pay to
- - softmax
- In order to compute these , we use a small network
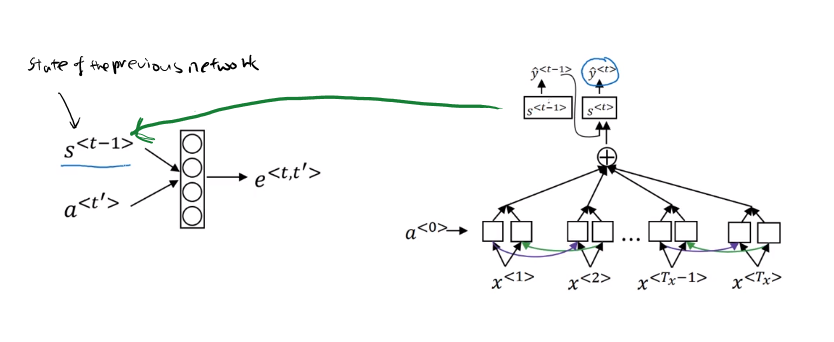
- is the hidden state of the RNN s, and is the activation of the other bidirectional RNN.
- One of the disadvantages of this algorithm is that it takes quadratic time or quadratic cost to run.