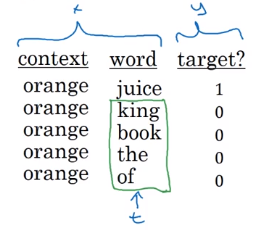
For example, we have the sentence: “I want a glass of orange juice to go along with my cereal”
We will choose context and target.
The target is chosen randomly based on a window with a specific size.
| Context | Target | How far |
|---|---|---|
| orange | juice | +1 |
| orange | glass | -2 |
| orange | my | +6 |
We have converted the problem into a supervised problem.
This is not an easy learning problem because learning within -10/+10 words (10 - an example) is hard.
We want to learn this to get our word embeddings model.
Word2Vec model:
Vocabulary size = 10,000 words
Let’s say that the context word are c and the target word is t
We want to learn c to t
We get ec by Eoc
We then use a softmax layer to get P(t|c) which is ŷ
Softmax:
where is the parameter associated with an output and is the number of vocabulary
Also we will use the cross-entropy loss function.
This model is called skip-grams model.
The overall flow is:
The last model has a problem with the softmax layer:
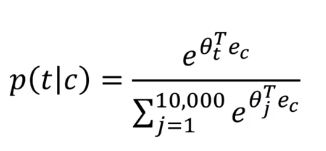
One of the solutions for the last problem is to use “Hierarchical softmax classifier” which works as a tree classifier.

In practice, the hierarchical softmax classifier doesn’t use a balanced tree like the drawn one. Common words are at the top and less common are at the bottom.
How to sample the context c?
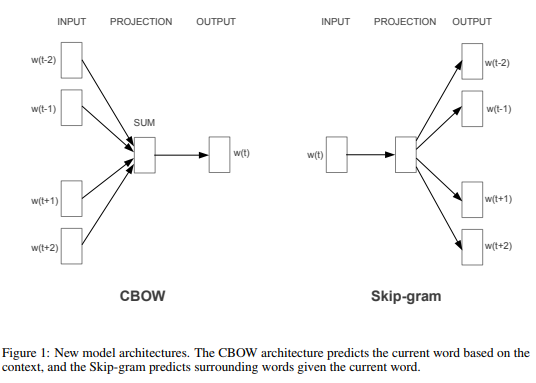
word2vec paper includes 2 ideas of learning word embeddings. One is skip-gram model and another is CBoW (continuous bag-of-words).
Negative sampling allows you to do something similar to the skip-gram model, but with a much more efficient learning algorithm. We will create a different learning problem.
Given this example:
I want a glass of orange juice to go along with my cereal
The negative sampling will look like this:

We get positive example by using the same skip-grams technique, with a fixed window that goes around.
To generate a negative example, we pick a word randomly from the vocabulary.
Notice, that we got word “of” as a negative example although it appeared in the same sentence.
So the steps to generate the samples are:
is recommended to be from to in small datasets. For larger ones - to .
We will have a ratio of negative examples to 1 positive ones in the data we are collecting.
Now let’s define the model that will learn this supervised learning problem:
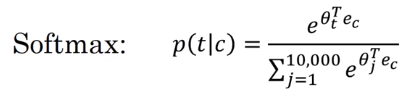
Lets say that the context word are c and the word are t and y is the target.

We will apply the simple logistic regression model.
The logistic regression model can be drawn like this:
Say the input word is Orange (one hot vector 6257),
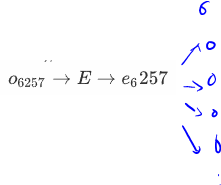
How to select negative samples: