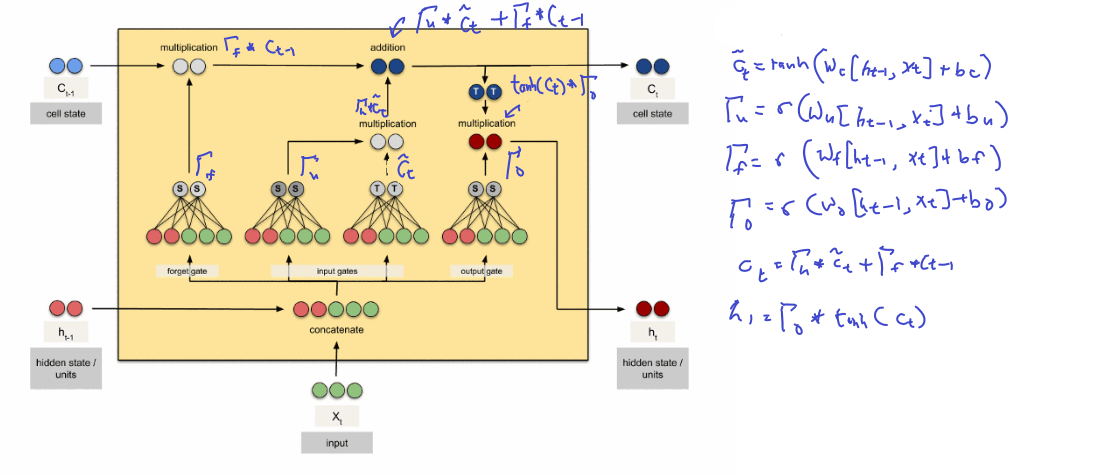
Original image from here before annotation
In motion
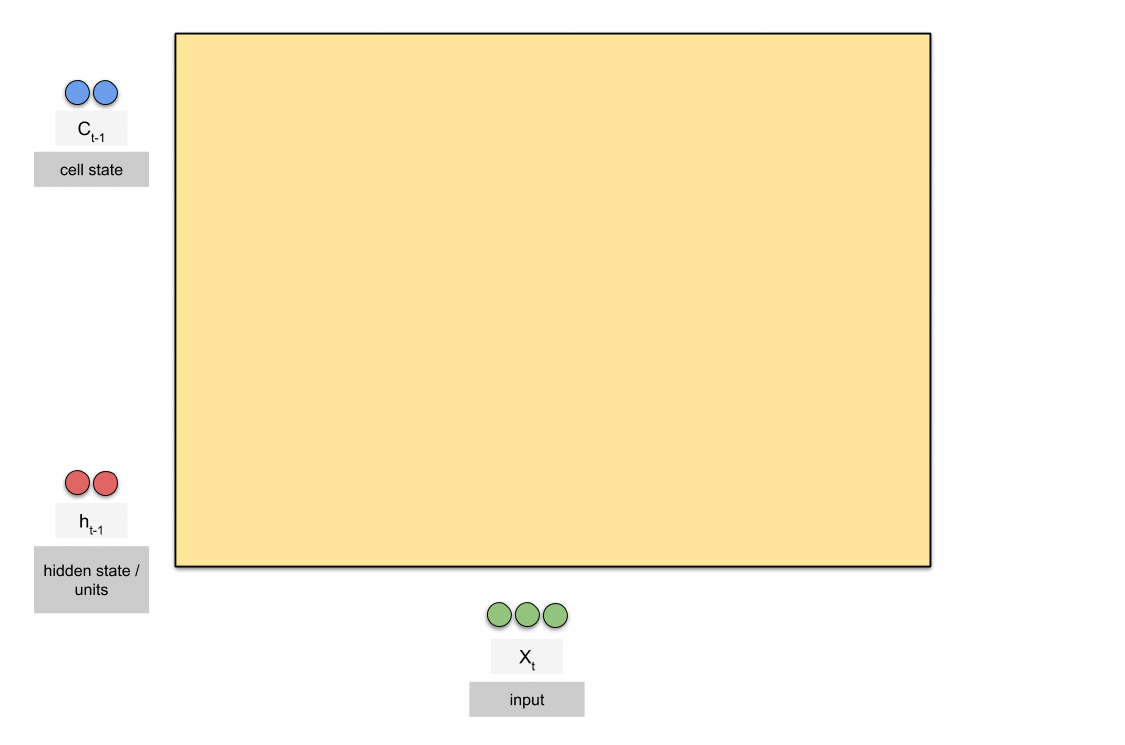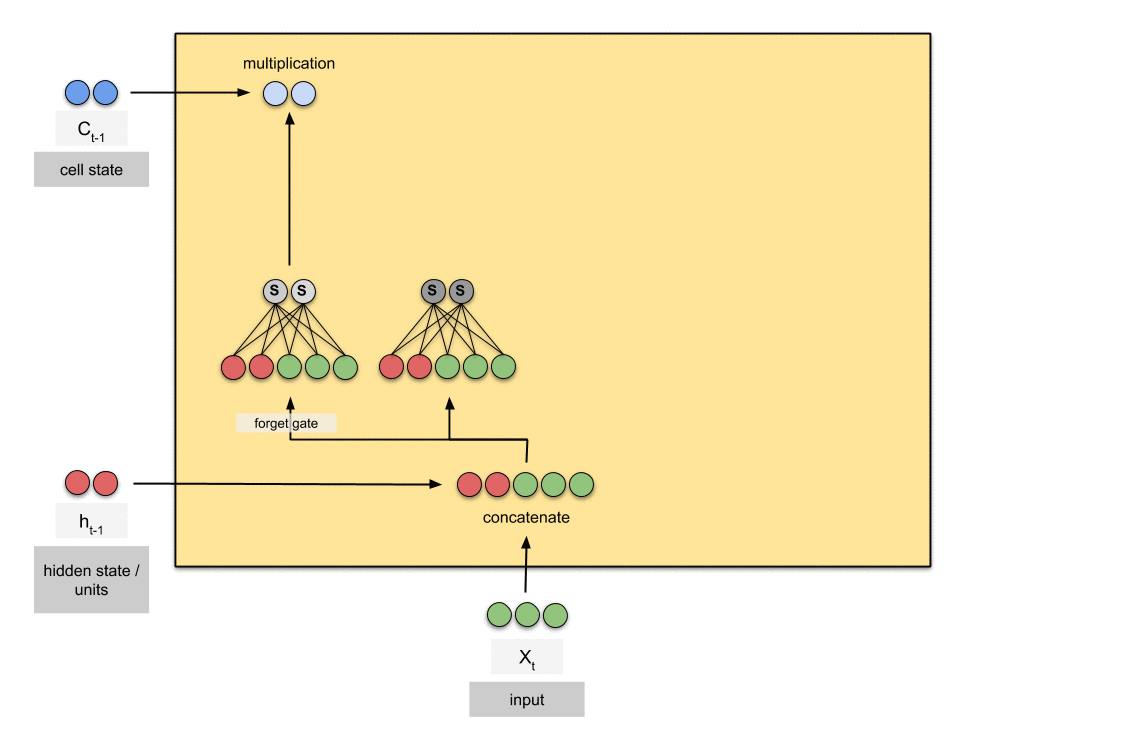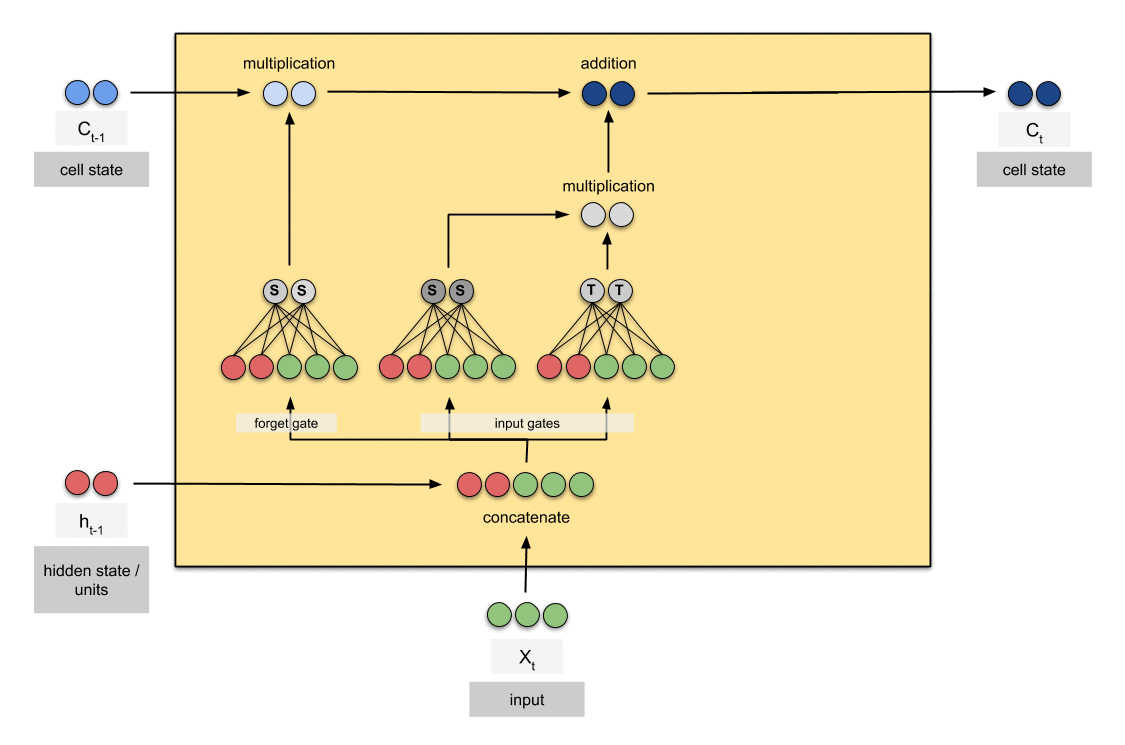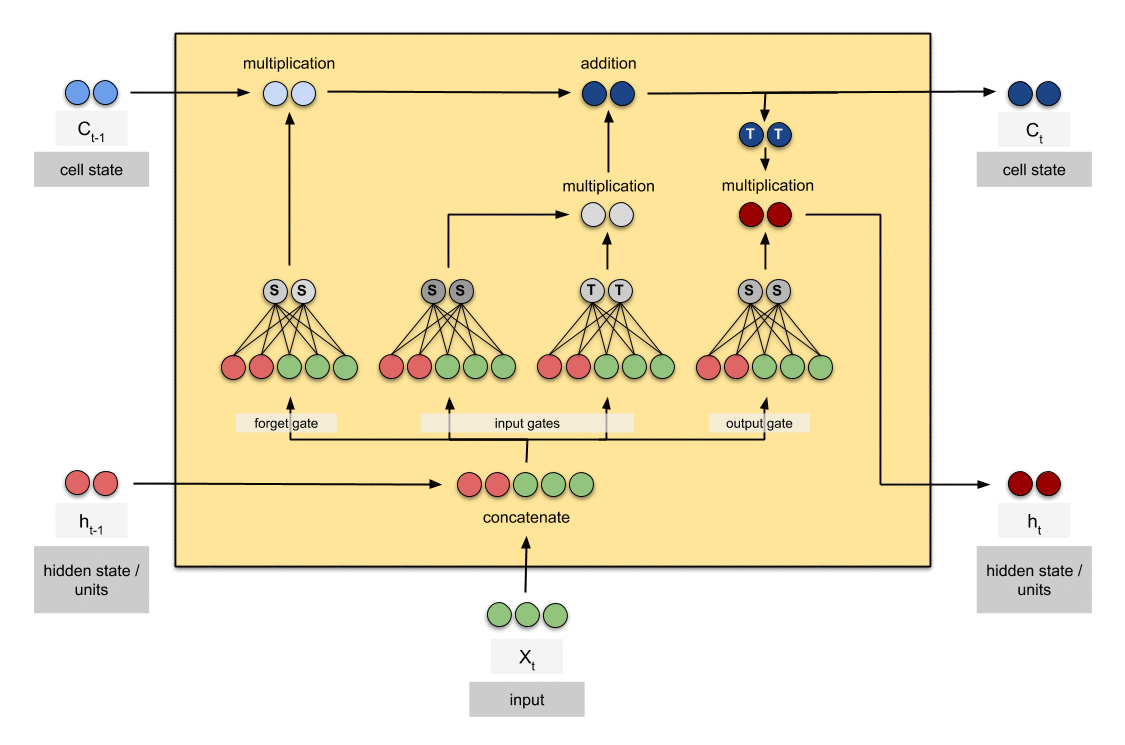
THis is much cleaner
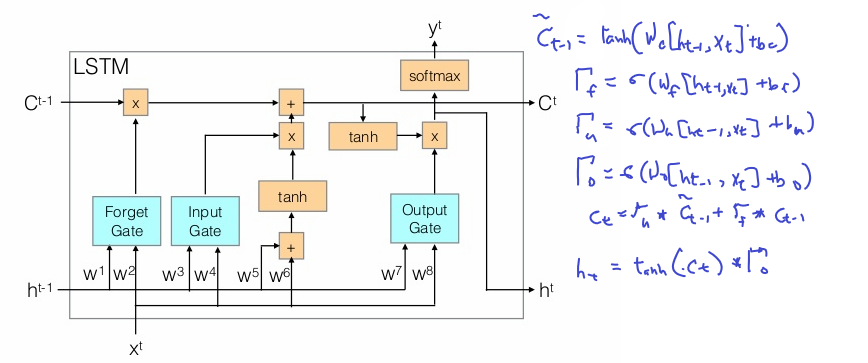
LSTM Cell in code
def lstm_cell_forward(xt, a_prev, c_prev, parameters): """ Implement a single forward step of the LSTM-cell as described in Figure (4) Arguments: xt -- Input data at timestep "t", numpy array of shape (n_x, m). a_prev -- Hidden state at timestep "t-1", numpy array of shape (n_a, m) c_prev -- Memory state at timestep "t-1", numpy array of shape (n_a, m) parameters -- python dictionary containing: Wf -- Weight matrix of the forget gate, numpy array of shape (n_a, n_a + n_x) bf -- Bias of the forget gate, numpy array of shape (n_a, 1) Wi -- Weight matrix of the update gate, numpy array of shape (n_a, n_a + n_x) bi -- Bias of the update gate, numpy array of shape (n_a, 1) Wc -- Weight matrix of the first "tanh", numpy array of shape (n_a, n_a + n_x) bc -- Bias of the first "tanh", numpy array of shape (n_a, 1) Wo -- Weight matrix of the output gate, numpy array of shape (n_a, n_a + n_x) bo -- Bias of the output gate, numpy array of shape (n_a, 1) Wy -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a) by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1) Returns: a_next -- next hidden state, of shape (n_a, m) c_next -- next memory state, of shape (n_a, m) yt_pred -- prediction at timestep "t", numpy array of shape (n_y, m) cache -- tuple of values needed for the backward pass, contains (a_next, c_next, a_prev, c_prev, xt, parameters) Note: ft/it/ot stand for the forget/update/output gates, cct stands for the candidate value (c tilde), c stands for the memory value """ Wf = parameters["Wf"] bf = parameters["bf"] Wi = parameters["Wi"] bi = parameters["bi"] Wc = parameters["Wc"] bc = parameters["bc"] Wo = parameters["Wo"] bo = parameters["bo"] Wy = parameters["Wy"] by = parameters["by"] # Concatenate a_prev and xt concat = np.zeros([xt.shape[0]+Wy.shape[1],xt.shape[1]]) concat[: n_a, :] = a_prev concat[n_a :, :] = xt ft = sigmoid(np.dot(Wf,concat)+bf) it = sigmoid(np.dot(Wi,concat)+bi) cct = np.tanh(np.dot(Wc,concat)+bc) c_next = np.multiply(ft,c_prev)+ np.multiply(it,cct) ot = sigmoid(np.dot(Wo,concat)+bo) a_next = np.multiply(ot,np.tanh(c_next)) yt_pred = softmax(a_next) # store values needed for backward propagation in cache cache = (a_next, c_next, a_prev, c_prev, ft, it, cct, ot, xt, parameters) return a_next, c_next, yt_pred, cache