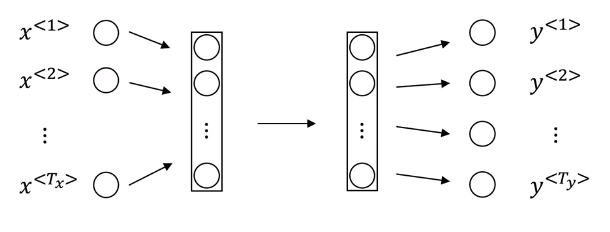
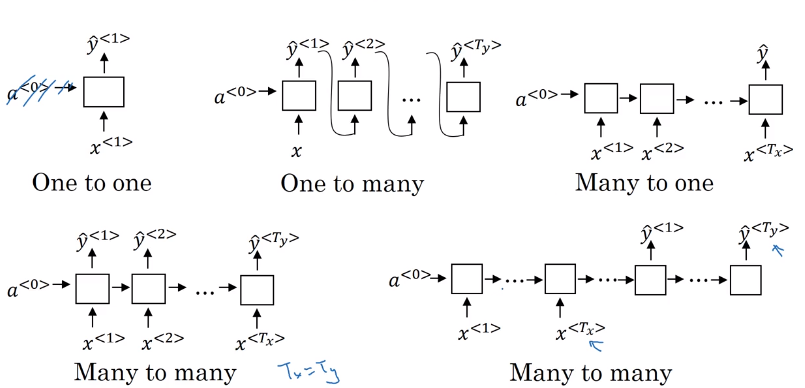
Problems:
Inputs, outputs can be different lengths in different examples.
Doesnt share fearues learned across different positions of text
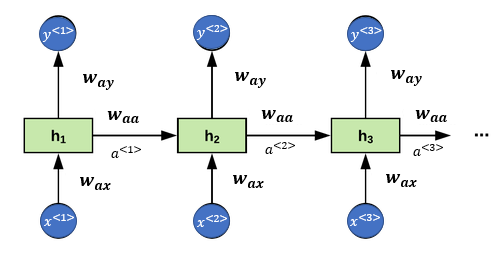
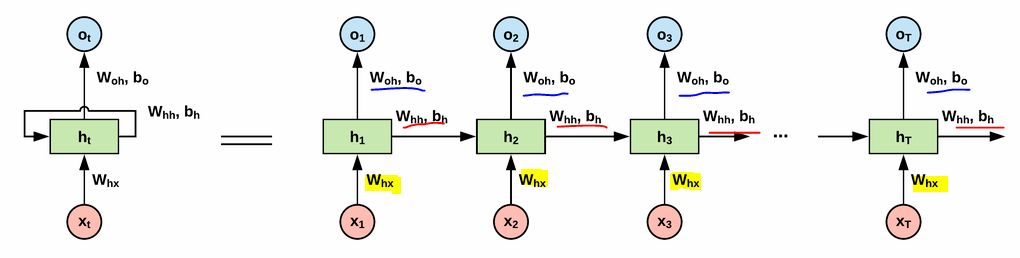 parameters are shared
parameters are shared
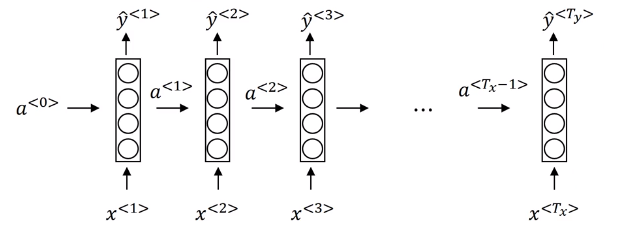
One weakness of this RNN is that it only uses the information that is earlier in the sequence to make a prediction.
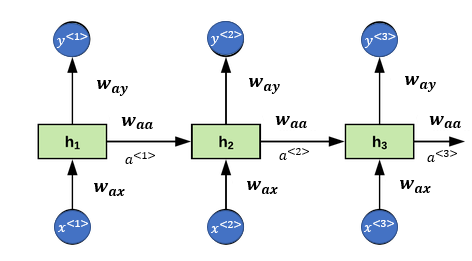
Start with
The second index means that this is going to be multiplied by some -like quantity, and The first index means that this is used to compute some -like quantity
is multiplied by some like quantity to compute a type quantity.
In RNN, tanh is very common choice. ReLu is sometimes used.
In generalized way
g will depends on what y as usual
This can be rewritten as:
If was a 100 dimensional, and was 10,000 dimensional, then would have been a 100 by 100 dimensional matrix, and would have been a 100 by 10,000 dimensional matrix.
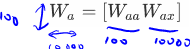
=
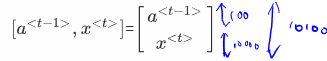
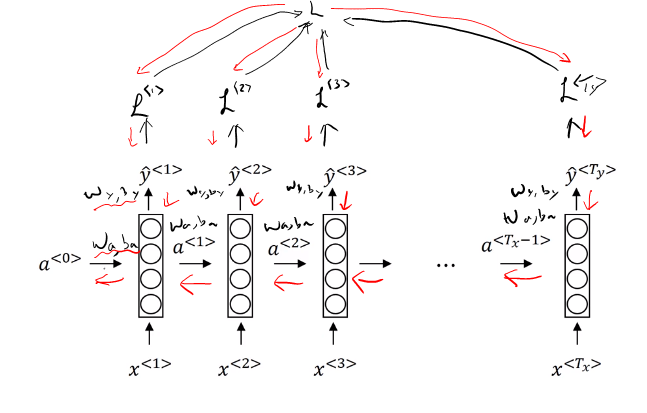
Backpropagation through time
Loss Function
Overall loss of sequence
Andrej Karpathy http://karpathy.github.io/2015/05/21/rnn-effectiveness/
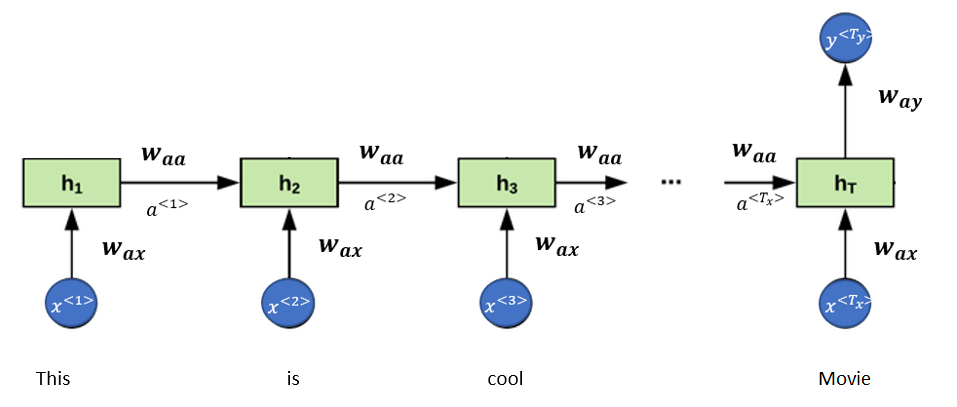
Use case: Sentence Classification
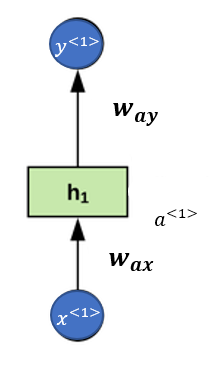
Use case: Music generalizations
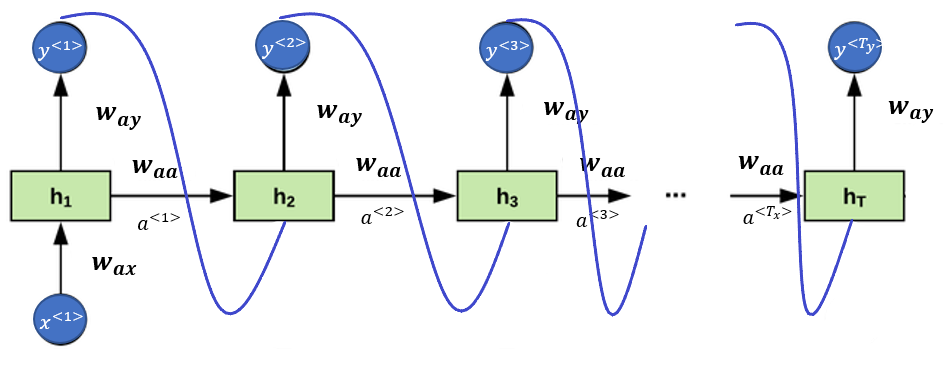
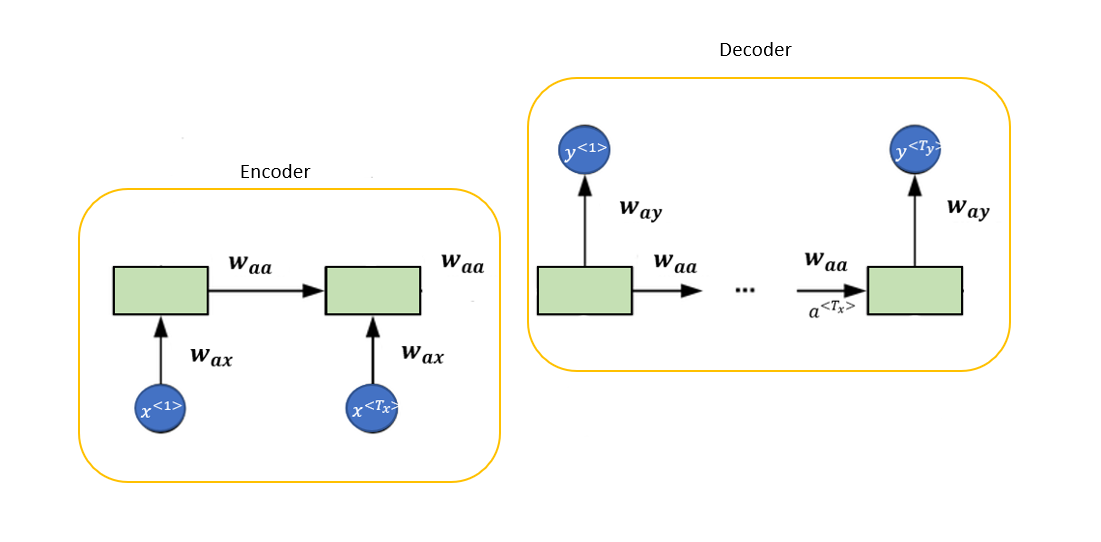
Translation
def rnn_cell_forward(xt, a_prev, parameters): """ A single forward step of the RNN-cell Arguments: xt -- Input data at timestep "t", numpy array of shape (n_x, m). a_prev -- Hidden state at timestep "t-1", numpy array of shape (n_a, m) parameters -- python dictionary containing: Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x) Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a) Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a) ba -- Bias, numpy array of shape (n_a, 1) by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1) Returns: a_next -- next hidden state, of shape (n_a, m) yt_pred -- prediction at timestep "t", numpy array of shape (n_y, m) cache -- tuple of values needed for the backward pass, contains (a_next, a_prev, xt, parameters) """ Wax = parameters["Wax"] Waa = parameters["Waa"] Wya = parameters["Wya"] ba = parameters["ba"] by = parameters["by"] a_next =np.tanh(np.dot(Wax,xt)+np.dot(Waa,a_prev)+ ba) yt_pred = softmax(np.dot(Wya,a_next) + by) cache = (a_next, a_prev, xt, parameters) return a_next, yt_pred, cache
def rnn_forward(x, a0, parameters): """ Implement the forward propagation of the recurrent neural network described in Figure (3). Arguments: x -- Input data for every time-step, of shape (n_x, m, T_x). a0 -- Initial hidden state, of shape (n_a, m) parameters -- python dictionary containing: Waa -- Weight matrix multiplying the hidden state, numpy array of shape (n_a, n_a) Wax -- Weight matrix multiplying the input, numpy array of shape (n_a, n_x) Wya -- Weight matrix relating the hidden-state to the output, numpy array of shape (n_y, n_a) ba -- Bias numpy array of shape (n_a, 1) by -- Bias relating the hidden-state to the output, numpy array of shape (n_y, 1) Returns: a -- Hidden states for every time-step, numpy array of shape (n_a, m, T_x) y_pred -- Predictions for every time-step, numpy array of shape (n_y, m, T_x) caches -- tuple of values needed for the backward pass, contains (list of caches, x) """ # Initialize "caches" caches = [] # Retrieve dimensions from shapes of x and parameters["Wya"] n_x, m, T_x = x.shape n_y, n_a = parameters["Wya"].shape # initialize a = np.zeros([n_a,m,T_x]) y_pred = np.zeros([n_y,m,T_x]) a_next =a0 # loop over all time-steps for t in range(T_x): # Update next hidden state, compute the prediction, get the cache a_next, yt_pred, cache = rnn_cell_forward(x[:,:,t], a_next, parameters) # Save the value of the new "next" hidden state in a a[:,:,t] = a_next y_pred[:,:,t] = yt_pred caches.append(cache) caches = (caches, x) return a, y_pred, caches