
In the sliding windows approach, the train classifier runs it across all of the different grid cells and run the detector to see if there’s a car, pedestrian, or a motorcycle. We could run the algorithm convolutionally, but one downside is that a lot of the regions have no object.
Russ Girshik, Jeff Donahue, Trevor Darrell, and Jitendra Malik proposed Region CNN. Instead of going through each step of sliding window approach, it tales only selected regions.
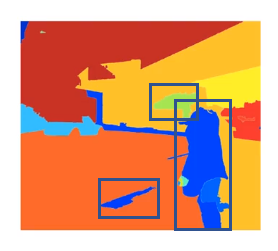
THey run a segmentation algorithm.

And run classifier on selected bounding boxes.
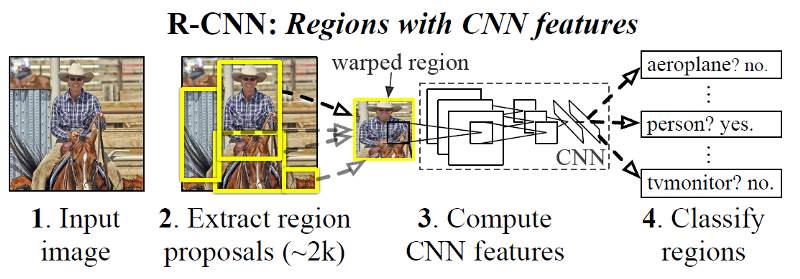
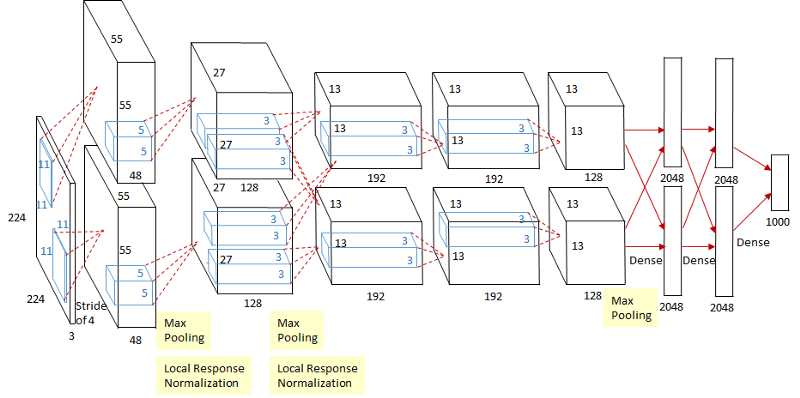
AlexNet is used to extract the CNN features.
It still takes a huge amount of time to train the network as you would have to classify 2000 region proposals per image. It cannot be implemented real time as it takes around 47 seconds for each test image. The selective search algorithm is a fixed algorithm. Therefore, no learning is happening at that stage. This could lead to the generation of bad candidate region proposals.
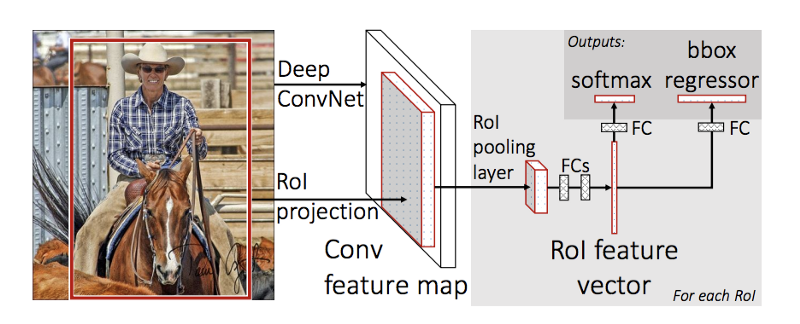 propose regions. Use convolution implementation of sliding windows to classify all the proposed regions.
propose regions. Use convolution implementation of sliding windows to classify all the proposed regions.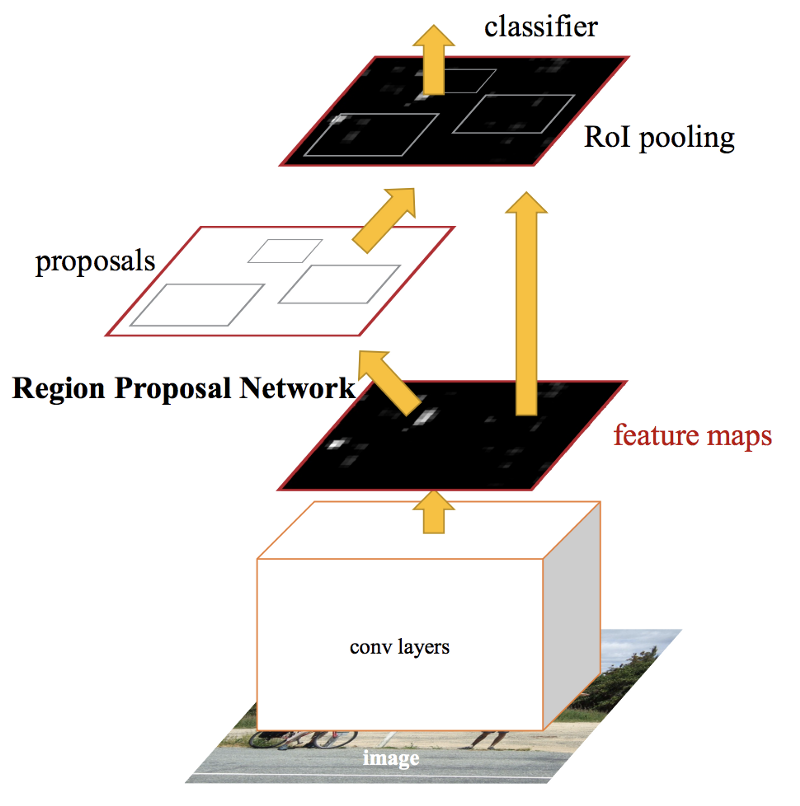
Girshik et al, 2013 Rich feature hierachies for accurate object detection and semantic segmentation Girshik et al, 2015 Fast R-CNN Ren at al., 2016 Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks