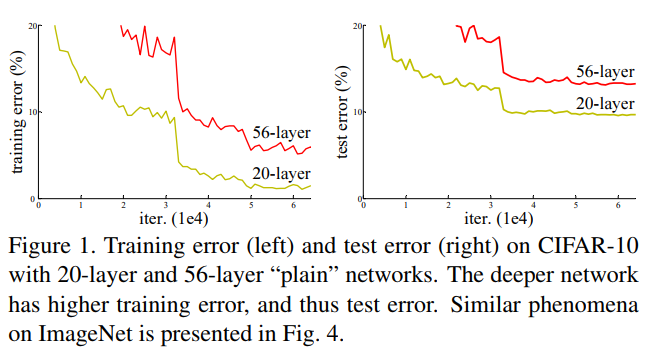
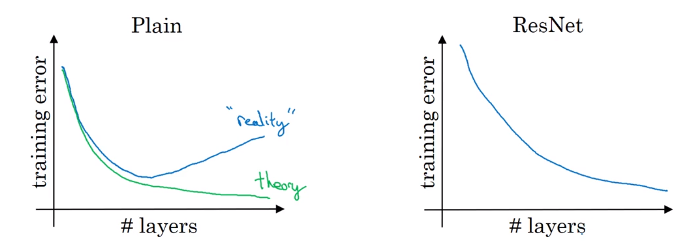
Very deep neural networks are difficult to train because of vanishing and exploding gradient types of problems. As the gradient is back-propagated to earlier layers, repeated multiplication may make the gradient infinitively small. As a result, as the network goes deeper, its performance gets saturated or even starts degrading rapidly.
Figure from He et al. paper [1]
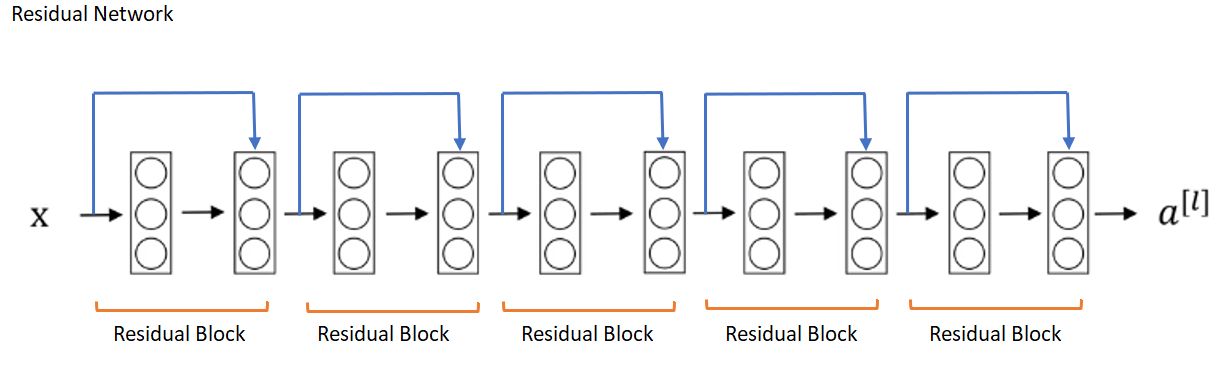
ResNet makes it possible to train up to hundreds or even thousands of layers and still achieves compelling performance.
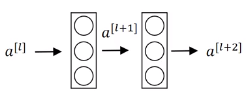
ResNets are built out of a residual block.
Main path between to can be represented as follow:
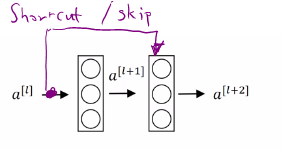
In residual network, is added to Relu activation to form a redisual block.
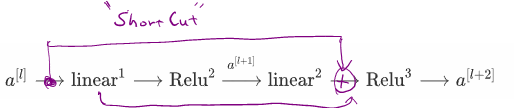
So,
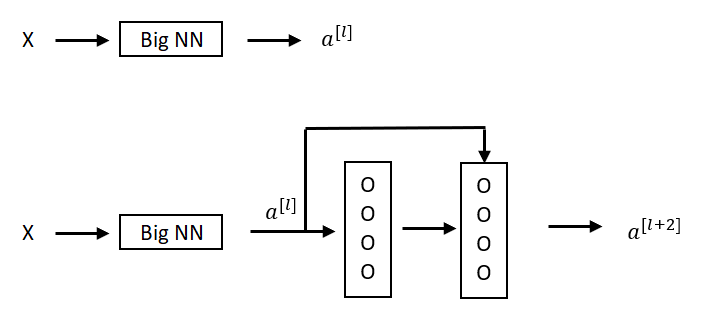
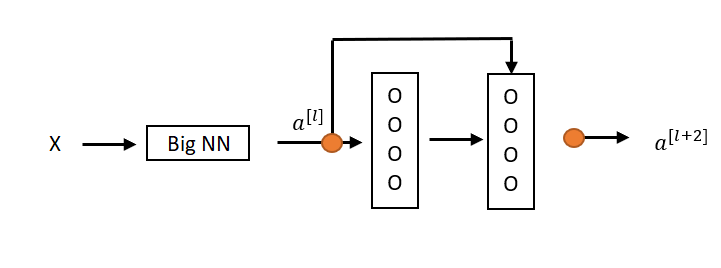
Example
ReLU,
For (1), we are assuming that and have the same dimension, so in ResNet, same convolutions are used and therefore, the input and the output represented as a .
In L2 regularisation weight decay, that will tend to shrink the value of .
If and , then =0, so (2) becomes
So, identity function is easy for residual block to learn. And it’s easy to get equals to because of this skip connection. Adding these two layers as in the second neural network above, it doesn’t hurt the neural network’s ability to do as well as the simpler network without these two extra layers, because it’s quite easy for it to learn the identity function to just copy to using despite the addition of these two layers.
For example, if is a 128 dimensional and or is 256 dimensional, we add an extra matrix called and would be dimensional matrix. can be learned parameters or fixed parameters.
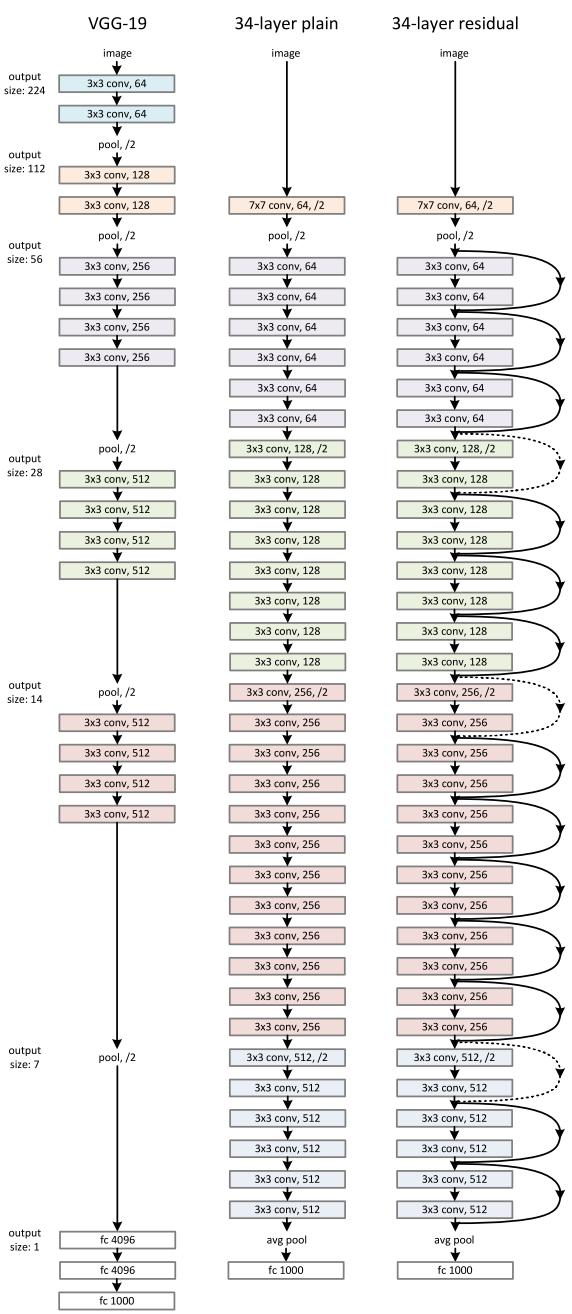
[1] K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. Deep Residual Learning for Image Recognition. arXiv:1512.03385,2015.