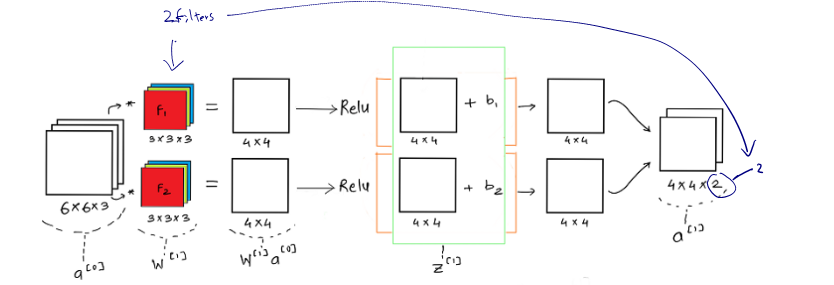
If we consider one layer of a convolution network without the pooling layer and flattening, then it will appear close to this:
In any given neural network
where is ReLU
It is important to understand that like in any other neural network, a convolutional neural network also has the input data which is an image here and model weights given by the filters F1 and F2 i.e. Once the weights and the input image is convolved we get the weighted output and then we add the bias .
One of the key functions here is the RELU activation function, which is rectified linear unit. Relu helps us add non-linearity to the learning model and helps us better train/ learn the model weights for the generalized case.
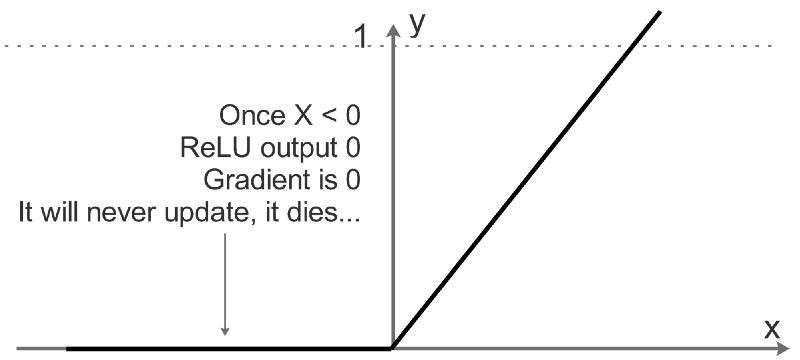
For values which are below a certain threshold ( here 0), the relu function doesn’t update the parameters at all. It simply dies. For a particular training example to be considered for training, it needs to have a set minimum value for the neuron to be activated. Also Relu helps us reduce the vanishing and exploding gradient problem faced in most deep neural network, as Relu provides efficient gradient propagation.
Problem: If you have 10 filters that are in one layer of a neural network, how many parameters does that layer have?
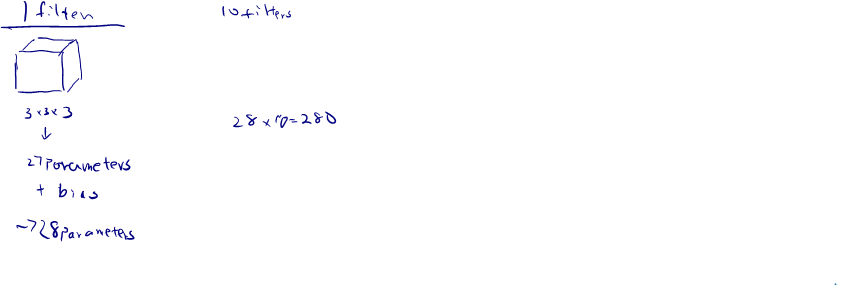
If layer is a convolution layer:
Filter size:
Padding:
Strided:
Number of filters:
Each filter: since the number of channels in your filter, must match the number of channels in your input
Activations:
Activation in vectorized implementation or batch gradient descent or mini batch gradient descent:
Weight:
bias:
Input:
Output:
Dimension of
Dimension of