In a deep learning era, more and more teams are now training on data that comes from a different distribution than your dev and test sets. There are some best practices for dealing with when you’re training and test distributions differ from each other.
Users will upload pictures taken from their cell phones, and you want to recognize whether the pictures that your users upload from the mobile app is a cat or not.
You care about data from mobile app but the number of samples are not large. What can we do?
Not Good Option
Put everythiong together, randomly shuffle to train, dev, and test.
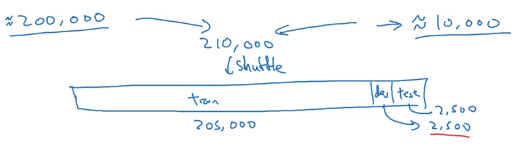
So this option is not good.
Good Option
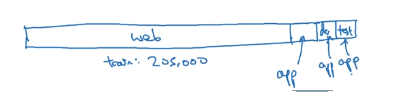
Disadvantage is that the distribution of training set is different from dev and test set.

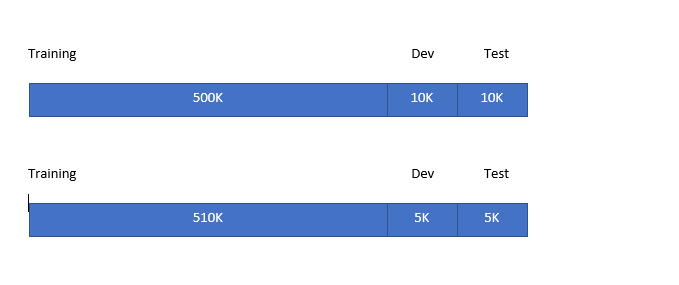
x=audio clip y=transcript
| Training | Dev/test |
|---|---|
| Purchased data | Speech activated rearview mirror |
| Smart speaker control | |
| voice keyboard | |
| 500,000 samples | 20,000 samples |
Options