One of the most important ideas has been an algorithm called batch normalization, created by two researchers, Sergey Ioffe and Christian Szegedy. Batch normalization makes your hyperparameter search problem much easier, makes your neural network much more robust. The choice of hyperparameters is a much bigger range of hyperparameters that work well, and will also enable us to much more easily train even very deep networks.
In logistic regression, normalizing the input speed up learning.
then normalize with variance
In deep learning, we normalize so train faster with batch normalization. Technically, it is achived by normalizing
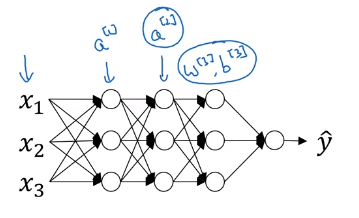
GIven some intermediate values in the neural network,
then normalizing
here we add to add stability in case turns out to be 0.
So every component of has mean 0 and variance 1. But we don’t want the hidden units to always have mean 0 and variance 1. Maybe it makes sense for hidden units to have a different distribution,
Here are learnable parameters of the model. Notice that the effect of and is that it allows to set the mean of to be whatever values. In fact, if is the denominator of and then the effect of is that it would exactly invert the equation . If that is true, then .
In the neural network, instead of using , now we can use .