Gradient descent with momentum
Gradient descent with momentum almost always works faster than the standard gradient descent algorithm.
The basic idea is to compute an exponentially weighted average of your gradients, and then use that gradient to update your weights instead.
-
Red position represents the minimum.

-
With one iteration of batch or mini-batch gradient descent

-
Second iteration of gradient descent

-
Gradient descent will slowly oscillate toward the minimum. This up and down oscillations slows down gradient descent and prevents you from using a much larger learning rate.
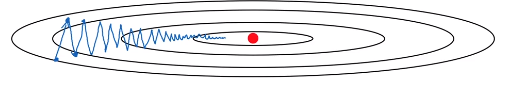
-
With a much larger learning rate you might end up over shooting and end up diverging. So to prevent the oscillations from getting too big forces you to use a learning rate that’s not too large.
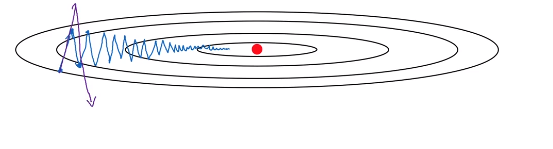
- For , you want slow learning
- For , you want faster learning, because you want to aggressively move from left to right toward the minimum.
Implementation of gradient descent with momentum
On iteration
Compute on current mini-batch
$
Then update parameters:
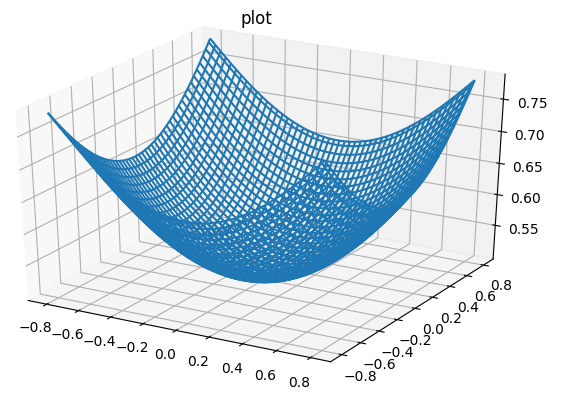
Imagein you have a bowl, and are acceleration, and and are velocity, and since is less than one, it act as a friction to limit the gradient decent to speed up.
$
Implementation details
On iteration
Compute on current mini-batch
$
Then update parameters:
Hyperparameters: ,
In general is a robust number
Bias correction: People usually do not do this because after just ten iterations, your moving average will have warmed up and is no longer a bias estimate:
Note
In some literature is ommited so,
$
The net effect of using this version in purple is that ends up being scaled by a factor of .
One impact of this is that if you end up tuning the hyperparameter , then this affects the scaling of and as well. And so you end up needing to retune the learning rate, , as well,