Mini Batch Gradient
Batch vs. mini-batch gradient descent
Vectorization allows efficient computation on examples.
What if ? You can get a faster algorithm if you let gradient descent start to make some progress even before you finish processing your entire, your giant training sets of 5 million examples.
Mini Batch: Small training sets, m=1,000
, etc. You would get
We can repeat this for
, etc. You would get
So, mini-batch :
Mini-batch gradient descent
for :
forward prop on
then compute cost =
- Backprogagation
- Update parameters
Epoch Single path through training set
Understanding mini-batch gradient descent
With batch gradient descent on every iteration you go through the entire training set and you’d expect the cost to go down on every single iteration.
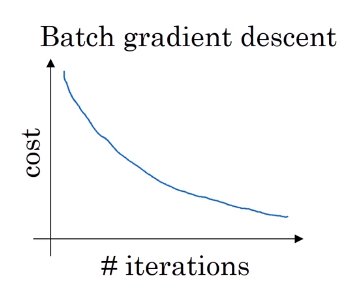
On mini batch gradient descent though, if you plot progress on your cost function, then it may not decrease on every iteration. If you plot J{t}, as you’re training mini batch in descent it may be over multiple epochs, you might expect to see a curve like this.
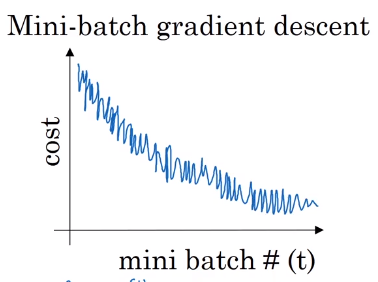
Choosing mini-batch size
- If mini-batch size , then you end up with batch gradient descent.
- If mini-batch size , then you end up with stochastic gradient descent and every examples are mini-batch
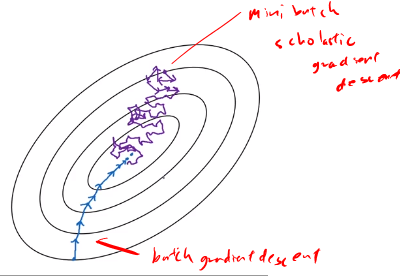
- In practice choose somewhere between 1 and m
- Batch gradient descent: mini-batch size , and takes too much time per iteration, since the size is big for each iteration.
- In between 1 and : fastest learning.
- lots of vectorization
- make progress without needing to wait til you process the entire training set.
- Stochastic graident descent: Loose speed from Vectorization
- If you have a small training set: Us Batch Gradient Descent (m<2000)
- If you have big , then mini-batch size is 64, 128, 256, 512
- Make sure your mini-batch fit CPU and GPU memory