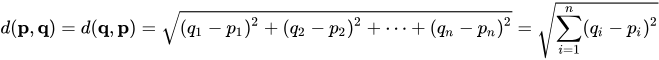
for each :
Then compare against .
The Euclidean distance between points p and q is the length of the line segment connecting them ( ).
In Cartesian coordinates, if and are two points in Euclidean n-space, then the distance (d) from p to q, or from q to p is given by the Pythagorean formula:
This is the sum of squares of elements of the differences, and then you take a square root, as you get the Euclidean distance.
Distance
Good
Dobule check
Worry
is a typical
Don’t use gradient checking in training, but only to debug, because computing for all the values of is very slow computation.
If algorithm fails gradient check, look at components (such as ) to try to identiy bug. If is very far from , look at the different values of to see which are the values of that are really very different than the values of .
Remember regularization - and is a gradient of J with respect to which includes regularization term.
Doesn’t work with dropout, because in every iteration, dropout is randomly eliminating different subsets of the hidden units. There isn’t an easy to compute cost function J that dropout is doing gradient descent on. It turns out that dropout can be viewed as optimizing some cost function J, but it’s cost function J defined by summing over all exponentially large subsets of nodes they could eliminate in any iteration. So the cost function J is very difficult to compute, and you’re just sampling the cost function every time you eliminate different random subsets in those we use dropout. So it’s difficult to use grad check to double check your computation with dropouts. So it is recommended to implement grad check without dropout. You can set keep-prob and dropout to be equal to 1.0. and then turn on dropout and hope that the implementation of dropout was correct.
Run at random initializationl perhaps again after some training. It rarely happens, but it’s not impossible that your implementation of gradient descent is correct when and are close to 0 at random initialization. But as you run gradient descent and and become bigger, maybe your implementation of backprop is correct only when and is close to 0, but it gets more inaccurate when and become large. One solution is to run grad check at random initialization and then train the network for a while so that and have some time to wander away from 0 from your small random initial values. And then run grad check again after you’ve trained for some number of iterations.