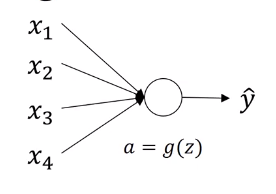
assuming
In order to avoid vanishing and explding gradient:
One reasonable thing to do would be to set the variance of , where is the number of input features that’s going into a neuron.
wl=np.random.rand(shape)*np.sqrt(1/n^(l-1))
For ReLU activation, variance of works better.
wl=np.random.rand(shape)*np.sqrt(2/n^(l-1))
For tanh activation, variance of works better. This is called Xavier initialization.
wl=np.random.rand(shape)*np.sqrt(1/n^(l-1))
Another version we’re taught by Yoshua Bengio for tanh activation variance of .
wl=np.random.rand(shape)*np.sqrt(2/(n^(l-1)+n^l))
This doesn’t solve valinishing/exploding gradients, but it helps.
This variance is one of the hyperparameter but the effect can be small.