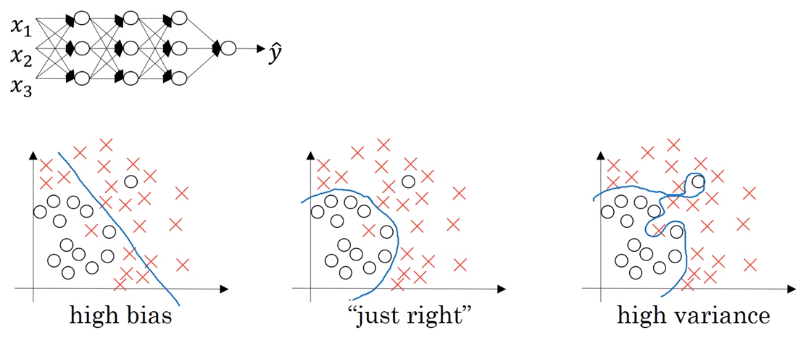
To reduce variance or prevent overfitting, regularization is one of the tool to be used.
In logistic regression, we want to minimize the cost function.
where and .
To add regularization to the logistic regression, you add times the norm of squared. is called the regularization parameter.
L2 Regularization: . is much more commong in deep neural network$
L1 Regularization: .
L1 regularization will make sparse. (More zeros)
In neural network, we have a cost function;
To add regularization to the neural network, you add times .
where because w: matrix. This is called
from backpropagation and parameter .
L2 regularization is also sometimes called .
Mathmatically,
It is called ‘weight decay’ because the first tem is multipling which is less than
So why is it that shrinking the L two norm or the Frobenius norm or the parameters might cause less overfitting? It sets the weight to be so close to zero for a lot of hidden units that’s basically zeroing out a lot of the impact of these hidden units. And if that’s the case, then this much simplified neural network becomes a much smaller neural network. In fact, it is almost like a logistic regression unit, but stacked most probably as deep.
Another reason
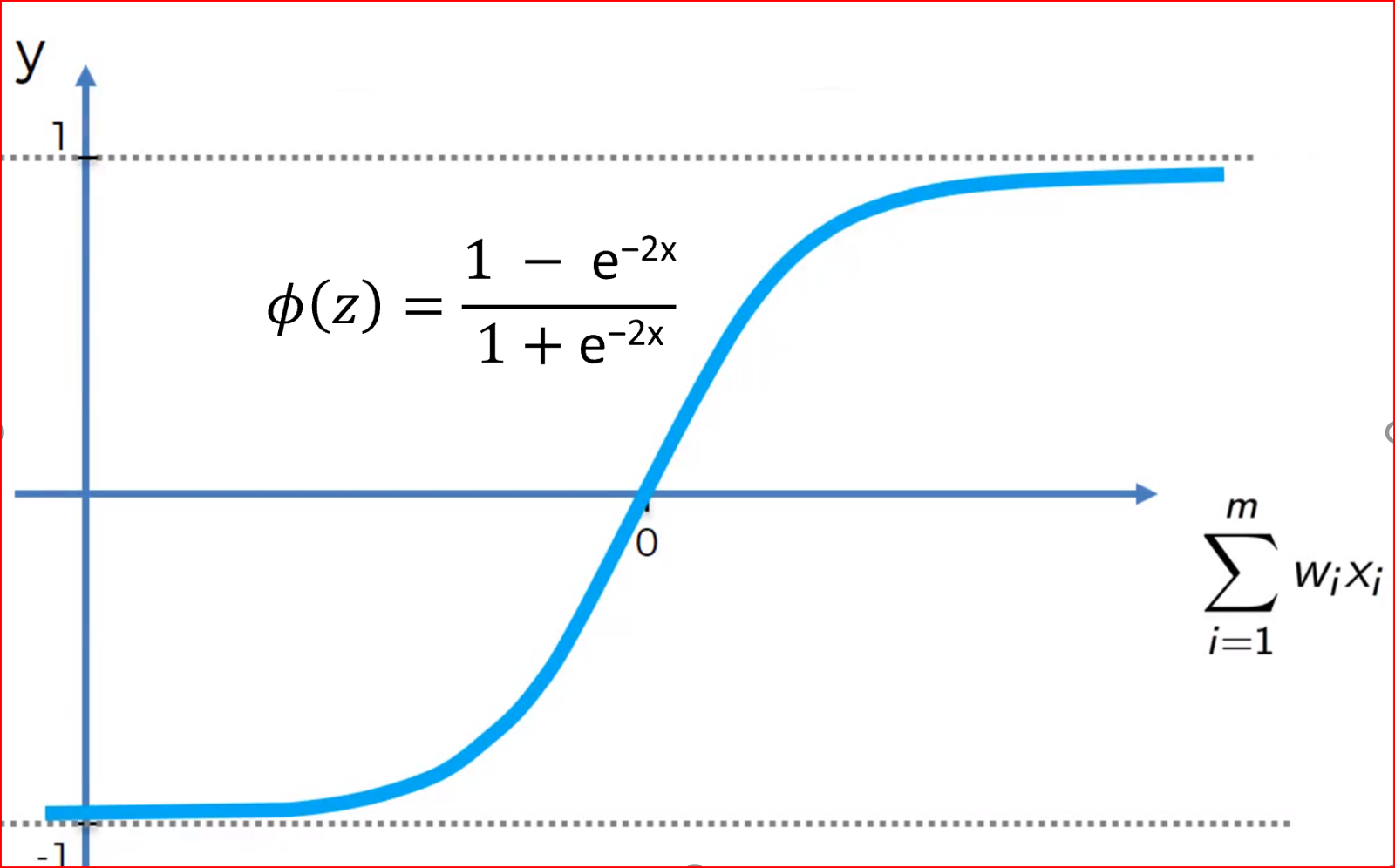
g(z): tanh(z) When z is close to zero, then we are using the linear regime of the tanh function. If is large, then is small, and is also small since , and if z is closer to 0, then every layer is linear.