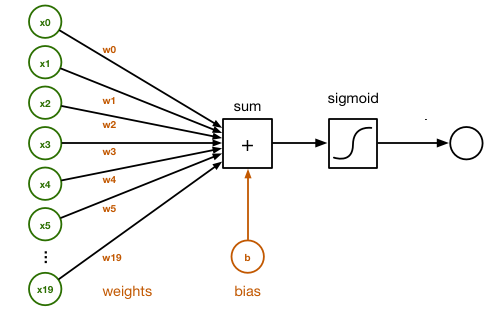
Parameters for a single layer neural network: , , ,
If
input features ,
Hidden units,
Output units$:
Matrix of is ,
Matrix of is ,
Matrix of is ,
Matrix of is ,
where
To train the algorithm, you need to compute gradient descent. When you are training a neural network it is important to initialize the parameters randomly rounded into all zeros.
Repeat
Based on chain rule, .
, , if there is single training example.
so, the shape of ,
The shape of and are
The shape of and are
We do this for other elements and you will have: