Activation Functions (活性化関数)
Sigmoid Activation Function (シグモイド関数)
Given x:
We used function as an activation.
- The output is so it can be used for binary classification.
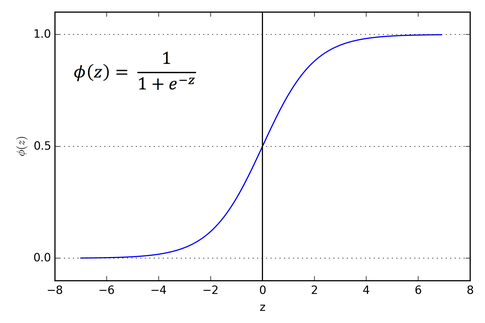
Non Linear Activation Function
- could be a nonlinear function that may not be the sigmoid function.
tanh Activation Function
1990年代になり、活性化関数は原点を通すべきと言う考えから、標準シグモイド関数よりもそれを線形変換した tanh の方が良いと提案された Yann LeCun; Leon Bottou; Genevieve B. Orr; Klaus-Robert Muller (1998). Efficient BackProp
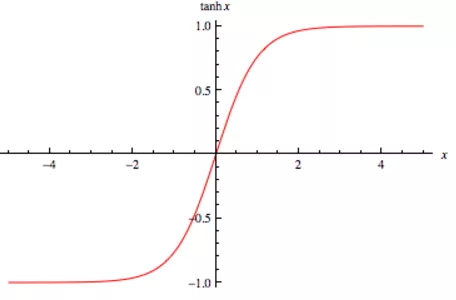
- This is a shifted version of sigmoid function
- The curve crosses (0,0) and the values are between -1 and 1.
- The output is and the tanh function is almost always strictly superior.
- One of the downsides of both the sigmoid function and the tanh function is that if z is either very large or very small, then the gradient or the derivative of this function becomes very small.
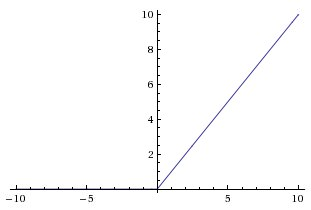
Rectify Linear Unit ランプ関数
Yann LeCun やジェフリー・ヒントンらが雑誌ネイチャーに書いた論文では、2015年5月現在これが最善であるとしている。 Yann LeCun; Yoshua Bengio; Geoffrey Hinton (May 28, 2015). “Deep learning”. Nature 521 (7553): 436-444. doi:10.1038/nature14539
Leaky Rectify Linear Unit ランプ関数
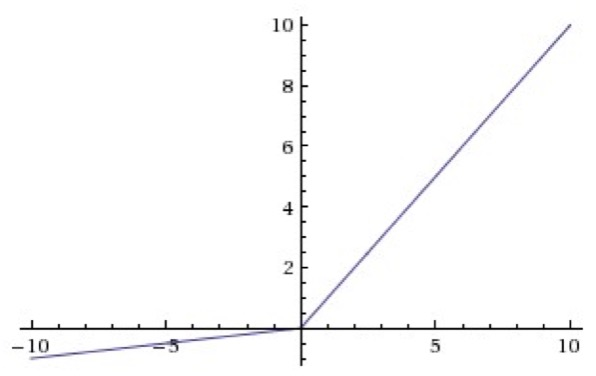
Andrew L. Maas; Awni Y. Hannun; Andrew Y. Ng (2013). Rectifier Nonlinearities Improve Neural Network Acoustic Models
Rules of Thumb
| Activation function |
Formula |
Type of classification |
|
|
binary classification |
|
|
|
| ReLU(z) |
max(0,z) |
Default |
| Leaky ReLU(z) |
max(0.01z, z) |
Works better than ReLU |
- Your neural network will often learn much faster with ReLU and Leaky ReLU activation than when using the tanh or the sigmoid activation function
Why do we need non-linear activation functions?
LEt’s eliminate non-linear function from the formulas above:
use linear activation function:
So,
If activation function is a linear function, then the output is also the linear function. So if you have a deep neural network without an activation function (with a linear activation function), it is just computing the linear activation function repeadetly. The linear functions in the hidden units are useless.
- For regression problem in machine learning, you use a linear function for the output layer since , but the hidden layer should use the non-linear activation function such as ReLU and tanh.