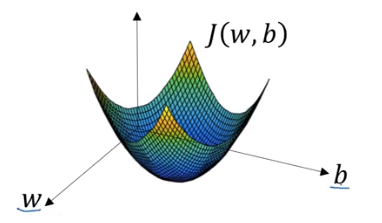
Cost function measures how well the parameters w and b are doing on the entire training set. The cost function has its own curve and its own gradients. The slope of this curve tells us how to update our parameters to make the model more accurate.
Want to find parameters w and b that minimize
Height is considered the loss function. is a single convex.
To find a good value for the parameters, we initialize and to some initial value and for logistic regression usually you initialize the value to zero. Random initialization also works, but people don’t usually do that for logistic regression. But because this function is convex, no matter where you initialize, you should get to the same point or roughly the same point. What gradient descent does is it starts at that initial point and then takes a step in the steepest downhill direction. So after one step of gradient descent you might end up there, because it’s trying to take a step downhill in the direction of steepest descent or as quickly downhill as possible.
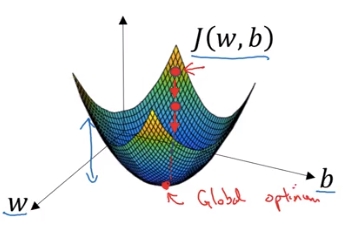
Gradient descent will bring the red dot to the global optimum.
Let’s look gradient descent in 2 dimension space.
Gradient descent repeats
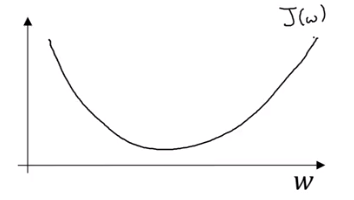
so is the slope of function
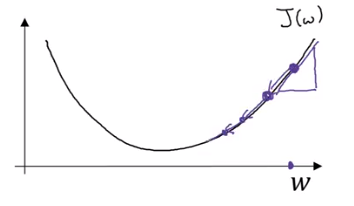
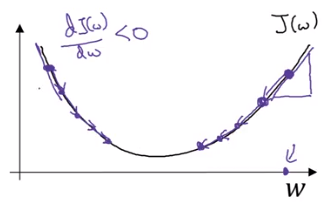
When , increases
is used in the code

When then .
When then .
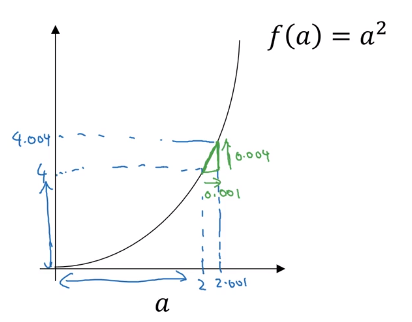
So a slope that is the derivative of at is . To write this out of our calculus notation, we say that when a=2 because we see that by nudging a up by .001, f(a) goes up 4 times as much.
When then .
When then .
So a slope that is the derivative of at is . To write this out of our calculus notation, we say that when a=5 because f(a) goes 10 times as much.
Derivative:
So, when you nudge by 0.001 upward, you will expect to go up by .
If then the derivative and if , . If we nudge by 0.001, then and so f(a) went upward by 4 times, and .
If then the derivative and if , . If we nudge by 0.001, then and so f(a) went upward by 12 times, and . So nudging by 0.001, it goes upward by
If or then the derivative and if , . If we nudge by 0.001, then and so f(a) went upward by 0.0005, and , so nudging by 0.001, it goes upward by half of 0.001 which is 0.0005.