, where Given m training example: and want
The prediction on sample i will be , where where
for th sample
we want this to be as small as possible.
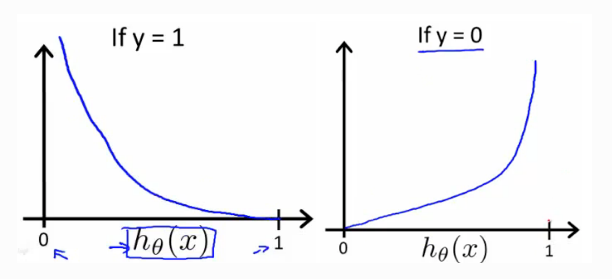
In logistic regression people don’t usually do this because when you come to learn the parameters, you find that the optimization problem which we talk about later becomes non-convex. So you end up with optimization problem with multiple local optima. So gradient descent may not find the global optimum.
In logistic regression, the loss function can be defined as
is the prediction of item .